
Try Gemini Flash 2.0 on Your Workloads: Comparable Capability to GPT-4o, 25x Cheaper & 5x Faster.


Deepseek R1, OpenAI O3, and Gemini 2.5 Pro have captured the world's attention due to their capabilities and the ability to see the model "think out loud" on simple queries. Perhaps as a result, the best recently released workhorse model was overshadowed. Gemini 2 Flash is my go-to model for building LLM applications because it is cheap, fast, smart, and features a massive context window.
Ideally, we could always use the most capable model for every task. However, the most capable models come with increased costs and longer latency. In many applications, the most intelligent model is not needed in order to do a great job. Up until the release of Gemini 2 Flash, this low cost niche was primarily filled by models such as Claude Haiku, Gemini 1.5 Flash, GPT-4o-mini, and a handful of open-weight models in specialized use cases. These models are not nearly as intelligent as GPT-4o or Claude Sonnet 3.5/3.7. They were typically only used when the cost of using a more advanced model was prohibitive. Gemini 2 Flash offers the price point of cheaper models while rivaling the capability of the best non-reasoning models.
5x-8x Longer Context window enables more applications
With a 1 million token context window, Gemini 2 Flash outpaces GPT-4o’s 128K context by 8× and Anthropic's by 5×. This extended context ability opens up possibilities that are not achievable with other models:
Ingesting entire multi-file codebases to generate context-aware suggestions
Enabling many-shot prompting with rich, prior examples
Processing large collections of documentation, extensive email histories, entire books, and multiple PDFs
Cheap to the Point You Don’t Have to Consider Cost
[Upload Image 2 here: Likely a cost comparison chart/graphic.]

Gemini 2.0 Flash is 25× cheaper than GPT-4o. There is even a free tier with high rate limits that can be used for non-sensitive work. So not only do you have access to that long context, but you can also use it regularly or run the model on a larger number of tasks at your organization—email, messages, logs, and more. Content that you previously thought wasn’t worth using an LLM for, or that you might consider processing with a specialized small model, can be processed using Gemini 2.0 Flash. The low cost also opens up processing of full videos, something that would often be cost-prohibitive with other multi-modal models.
Generous Free Usage: The free tier comes with ample rate limits—15 requests per minute and 1,500 requests per day—allowing you to test and iterate without any upfront cost. Be aware that your use of the free tier means that your data can be used by Google to improve their products, so only use the free tier for non-sensitive information, such as public documents.
Highly capable
Despite its low cost and high speed, Gemini 2.0 Flash remains highly capable across reasoning, coding, and multi-turn dialogue:
Coding and Reasoning: Claude Sonnet 3.7 leads in coding tasks, with Gemini 2.0 Flash close behind and GPT-4o trailing in third.
Multi-Turn Conversation (MultiChallenge Benchmark):
In realistic multi-turn conversations, Gemini Flash scored 36.88, outperforming GPT-4o (27.81) and trailing Claude Sonnet (42.89). It handles instruction retention, coherent follow-ups, and long-context conversation far better than its cost would suggest.User Preference (LMSYS Arena Elo):
Gemini Flash scores 1283, closely behind Claude Sonnet (1300) and GPT-4o-11-20 (1318). These scores imply GPT-4o would win about 56% of head-to-head matchups with Gemini Flash—just a modest edge. Claude would be expected to win ~53% of comparisons. The models are clustered closely, suggesting Gemini Flash performs nearly as well as top-tier models, while being drastically cheaper and faster.
Gemini 2.0 Flash: Unmatched Speed and Responsiveness at Scale
Gemini 2.0 Flash delivers class-leading speed, critically maintaining performance even with demanding 100,000-token inputs where others lag. This translates directly to smoother, real-time user experiences.
Performance Showdown at 100K Tokens:
Instant Responsiveness (Time to First Token): How quickly does the model start responding?
Gemini 2.0 Flash: 1.6s
vs. GPT-4o-mini: 5.0s (~3.1x Slower)
vs. GPT-4o (Nov '24): 11.6s (~7.3x Slower)
vs. Claude 3.7 Sonnet: 12.1s (~7.6x Slower)
Rapid Generation (Output Tokens Per Second): How fast is the complete answer generated?
Gemini 2.0 Flash: 355 TPS
vs. GPT-4o (Nov '24): 78 TPS (~4.6x Slower)
vs. Claude 3.7 Sonnet: 67 TPS (~5.3x Slower)
vs. GPT-4o-mini: 57 TPS (~6.2x Slower)
Why This Matters: Gemini 2.0 Flash eliminates the frustrating delays common with large contexts. Its ability to start responding up to 7.6x faster and generate text up to 6.2x faster enables truly interactive applications – from chatbots handling long histories to real-time analysis of extensive documents – where competitors introduce significant lag. It offers a rare combination of immediate responsiveness and sustained high throughput under pressure.
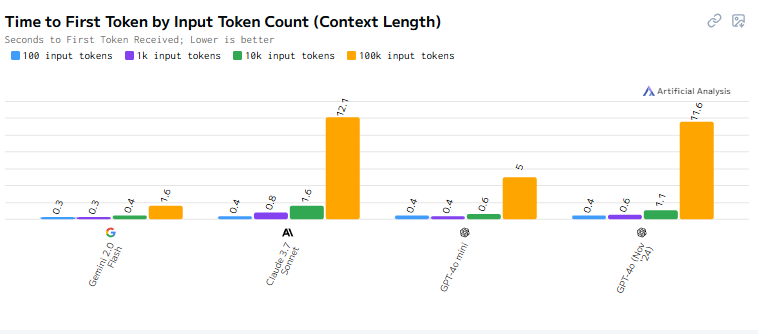

[Upload Image 3 here: Likely a graph showing Time to First Token comparison.]
[Upload Image 4 here: Likely a graph showing Output Tokens Per Second comparison.]
Easy Integration and Enterprise-Ready Deployment
Easy Integration: Leverage existing OpenAI-compatible SDKs (like the Python SDK) for quick implementation.
Platform Access: Use model ID gemini-2.0-flash-001 via Google AI Studio (for free tier access) or Vertex AI.
Enterprise Controls (Vertex AI): Deploy with confidence using features like US-only regions, ephemeral storage, logging controls, training opt-out, and optional DLP integration for compliance (HIPAA, GDPR).
Final Thoughts
Gemini 2.0 Flash fundamentally changes the calculus for building LLM applications. Its unique blend of massive context, near top-tier capability, extremely low cost, and exceptional speed makes it the standout choice for a vast range of tasks. It allows you to build more ambitious applications, worry less about retrieval perfection, and significantly reduce operational costs. While the absolute most complex reasoning might still warrant a premium model (if budget and latency permit), Gemini 2.0 Flash should be the go-to model for developers in 2025, dramatically accelerating development and enabling AI adoption where it was previously impractical.